With the rise of machine learning software (you can't say "AI" or else people will shriek about it) there has been great advances in many fields, such as mass surveillance, enhancement of vehicle ticketing systems, and many other awesome things that improve our lives day-to-day. But beyond these pleasant improvements to our daily lives as cogs in the corpo machine, there has also of course been the rise of systems designed to entertain us. DLSS from NVidia is being used to do bangin' upsampling in modern games such as the much discussed Cyberpunk 2077, virtual waifu software like xiaoice, and face detection based filters such as you see in zoom and snapchat. One thing that stands out to me are games built on generative text systems such as AI Dungeon.
If you haven't heard of it before, AI Dungeon is a text-adventure system where your choices are interpreted by a generative text model - that is, some ML that can generate text - and spits back a response. So you say what you do, and then AI Dungeon will say what happens, or in some cases put words in your mouth. It's a pretty fun system, and their more powerful "Dragon" model is based on GPT-2 from Open AI. The GPT line from Open AI is some pretty cutting edge stuff, although GPT-2 has since been superseded by GPT-3.
Machine learning models work generally by taking some input (in our case, text) and running it through a series of transformations, much like matrix transformations you'd see in game development, although these transformations are intentionally nonlinear. The goal of these transformations is to take the input and be able to do something interesting with them. Perhaps with a image processing model we could tell if something is a hotdog or not by transforming the pixel data to a space that gives a probability of hot doggyness. Doing this involves setting many internal numbers used for this tranformation (namely weights and biases) which are used to encode the transformative operations on the input data to reach the output space. During training of the model, the weights and biases are tuned algorithmically in order to maximize success (reduce a metric called "loss"). It works like this. You take some data which you already know whether it's a hotdog or not, preferably a huge fuckton of images of hotdogs and not-hotdogs, and split it into a training data set, and a validation set. You feed it training data, and based on whether it got the answer right to the question, the weights are adjusted. The algorithm used for this is called gradient descent. In doing this, the model is really learning to be good at classifying (or whatever result you want) the training data. Then you test it using the validation set you set aside to see how well you've done. There's some inherent risk in this. If you train too much on the training data, you get to a point called "overfitting." When a model is overfit, it has basically memorized all the training data rather than learned how to generalize the problem and classify all sorts of images.
Imagine if we have an overfit model for a text generator. It's been fed a bunch of partial sentences, and has memorized the sentence completion. Remember - a text generator is really just doing the task "finish this sentence." A good text generator will finish the sentence by producing something believable to be the output. However, an overfit text generator will do it by spitting out the rest of the sentence it trained on. If we are interacting with an overfit text generator, we can recover the training data simply by enumerating sentences and recording the results. And what if private information, like email addresses or credit card numbers were encoded in the training data? Or what if the training data is a company secret? Suddenly we have a big issue of leaking training data. However, machine learning models are designed not to be overfit, especially for this reason.
However however, it has been shown, such as in this paper from a bunch of intelligent folks and big corps that in language models (specifically GPT-2!) that even when a model is not overfit, we can still retrieve verbatim text sequences from the training data. Now, GPT-2 itself as a demo was trained using Reddit (god can you imagine forcing an AI to become a redditor? This kind of shit is why Tay.ai became a nazi). However, when you use GPT-2 yourself, you train it on other data that's relevant to the subject matter at hand. So we might be interested in what kind of data was used to train AI Dungeon's Dragon model.
Out of curiousity, I took a stab at it. I expected that certain highly-unique start-sequences (for example, "Copyright" or "ISBN Number") might have been memorized instead of generalized due to their infrequency of appearance in text. Once you're in an AI Dungeon game, there are certain settings you can use. If you use the "Creative" mode, you can feed text undecorated directly into the system. So it's easy, put in an interesting start-sequence, and let it run. You can hit the refresh looking button for it to regenerate. Let's try with the start-sequence "Copyright"
Copyright (c) 2016 by J.A. Michaels
Copyright (c) 2016, Ian T Smith.
Copyright (c) 2016 Ian Cheyser
Now, we need to make an informed decision as to whether or not the results coming back from this are really memorized or if they're just the model making up something that fits a copyright pattern. One of the hits I got in practice was a Copyright for "kain pathos crow." I thought this was pretty interesting since it's a really unique name - not really something we'd imagine as a common copyright. So let's google the dude.
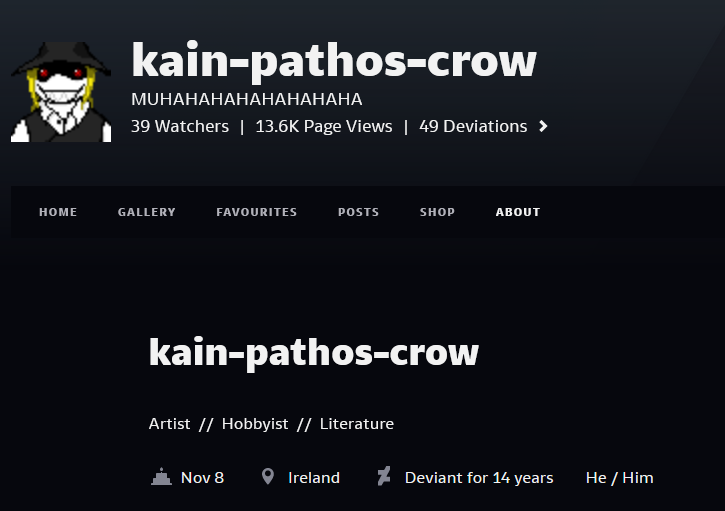
Bingo. This looks like a good hit. This guy is on deviantArt making literature. What's more, it seems like it's in a format which might be easy enough to insert into a training set.
We can also do the same thing with "http://"
http://www.writerscafe.org/
http://www.sincomics.com/ (LINK REMOVED)
https://www.wattpad.com/
Note that a lot of the stuff that was generated was bogus. It's pretty clear that the model seems to have a general idea of what some URL formats look like, however the ones above seem to be reasonable stuff that might have been used for initial training.
There are some other interesting properties. Dragon seems to have learned how to create youtube video links, ISBN numbers, email addresses, and telephone numbers.
Additionally, there seems to have been some attempt at scrubbing personal information and some links, such as the (LINK REMOVED) text you see above. If you try putting in "Call me at" then it will complete the sequence with some underscores, indicating that phone numbers were scrubbed prior to training. Also, somewhere along the lines, links were removed in the data cleaning process.
What can we learn from this, or how do we go deeper? If we wanted to really scrape out lots of training data, the next step would be to identify some high quality start-sequences and build some software to hit the system over and over with them, and keep ones that look good. For URLs this is simple. Just grab the URL in the output and try to dns resolve it. If it works, it's likely something memorized in training. If not, it's something the bot learned to cook up. We've found that ISBN numbers aren't a good signal, because they tend to just be random numbers in ISBN format. I tried, and whenever I did ISBN lookups, it came up bogus. Although, even there we do learn that the model was likely fed the content of entire books during training as well.
How certain are you about the results? Not at all. Well sort of. With results like our friend Kain, we can be certain of one of two things - his work was either used in initial training, or he uses AI Dungeon to write stories, and his interactions with the system were reused to train the system again, and for whatever reason he decided to put a copyright into the game while he was writing. However with results like the regular names we got, we can't really be certain these are real people.
We also learn a little about the training data from the fact that most of the copyrights that come back are from 2016 and 2017, which indicates this is likely when the training data was collected.
Well, what can we do with all this? Like most of my articles, not much. This is more of an exercise in curiousity after all. If we wanted to train a similar model, it would be useful as a jumping off point for collecting training data of your own, but it would still need to be cleaned and prepared for use in an ML model, and really that's the hard part aside from deciding on model architecture. But hey, this was fun, wasn't it? Go play with AI Dungeon's (awesome) Dragon model yourself, and see if you can learn anything about it. Or just, you know, have fun. It's a great little game.
stay comfy